
有问题就有答案
推荐视频
什么是“电子商务大数据”
阿里巴巴旗下的飞天大数据平台有什么实际用途
7月25日消息,阿里云飞天大数据平台亮相阿里云峰会上海站,拥有唯一自主研发的计算引擎,是全球集群规模最大的计算平台,最大可扩展至10万台计算集群,支撑海量数据存储和计算。在民生服务领域,飞天大数据平台已经“最多跑一次”、城市大脑等场景中,协助优化服务模式,实现更智能便捷的服务能力,保障信息安全。查看原图数据显示,目前飞天大数据平台可扩展至10万台计算集群,集群规模全球第一。单日数据处理量从2015年100PB、2016年180PB、2017年320PB,到2018年超过600PB,仅用三年时间提升5倍。在浙江,飞天大数据平台支撑下,“最多跑一次”打通与老百姓办事最密切相关的100个事项70多亿条数据,老百姓甚至有可能一次都不跑。在杭州,城市大脑实时指挥1300个红绿灯路口、200多名交警,从2016年到2018年,杭州从全国最拥堵城市排行榜上下跌52名。原来需要跑5个窗口、耗时2天才能拿到的新生儿出生证,现在只需在手机上动动手指,填9项信息,一个出生证就办好了;原来看一次病排队付几次费,现在可以看完回家再付钱……这样的场景正在越来越多的城市变为现实,背后有飞天大数据平台的支撑。据了解,该平台的研发源自阿里巴巴的自身实践。十年前,新兴互联网业态蓬勃发展,中小企业在阿里巴巴电商平台上爆发式增长,商家第一次具备直接触达消费者的普惠渠道,激发庞大的消费者需求,海量数据击垮传统IT架构。在此背景下,阿里巴巴开始探索全新的技术来支撑爆发式增长的数据存储和计算需求。大部分企业的惯例是直接使用国际开源的数据计算框架Hadoop。在阿里巴巴内部,也曾出现过激烈的争论,究竟是直接使用开源Hadoop,还是从每一行代码写起,自主研发一个大数据平台。当时,电子商务蓬勃发展,人类社会从未有过如此规模的商业交易在一个互联网平台上进行,如果用Hadoop搭建的大数据平台,必将在不久的未来再次遇到挑战,更别提为外部企业提供服务,成为普惠的IT基础设施。由此,阿里巴巴坚定投入飞天大数据平台研发,将成千上万台服务器组成一台超级计算机,向社会提供水电煤一样的公共服务。早在2012年初,阿里巴巴技术委员会王坚就表示,“从战略上来说,阿里云想做的事情实际上可以解读为Amazon+Google并有所超越。将单一集群做到数千乃至更高,技术上是国家和企业竞争力的标志。阿里巴巴必须攻克这道难关。”也正是因为这一坚持,才有了今天唯一自主研发的飞天大数据平台。过去十年,飞天大数据平台打破了多个记录:2013年,突破了单集群内5000台服务器同时计算的局限,如今单集群已超过1万台的规模;2015年,打破计算界SortBenchmark的4个世界纪录,用不到7分钟便完成了100TB的数据排序,刷新了ApacheSpark 23.4分钟的纪录。
都说现在是大数据时代,那么如何获取自己想要的数据呢
{!-- PGC_VIDEO:{"status": 0, "thumb_height": 360, "group_id": 6479608097751957774, "media_id": 5567486222, "vname": "\u90d1\u6770\u77ed\u89c6\u9891.mov", "vid": "v02004g10000ceeaembc77u4p1vjs85g", "video_size": {"high": {"h": 480, "subjective_score": 0, "w": 854, "file_size": 8954194.0}, "ultra": {"h": 720, "subjective_score": 0, "w": 1280, "file_size": 17343442.0}, "normal": {"h": 360, "subjective_score": 0, "w": 640, "file_size": 6520726.0}}, "sp": "toutiao", "vposter": "-sign.toutiaoimg.com/mosaic-legacy/403100009dcb797d9f96~noop.image?x-expires=1989250202&x-signature=NfESvA9OVF%2FHQFD5ntXgmzLYKds%3D", "external_covers": [{"mimetype": "webp", "source": "dynpost", "thumb_height": 360, "thumb_url": "3f57000830b4f7c702c2", "thumb_width": 640}], "thumb_width": 640, "duration": 186, "hash_id": 17943679761860598237, "vu": "v02004g10000ceeaembc77u4p1vjs85g", "item_id": 6477002368775881230, "user_id": 5567358271, "thumb_url": "403100009dcb797d9f96", "md5": "64117f58768a7b5fc7972b8c44f9b9b1", "neardup_id": 17943679761860598237} --}
谢邀。这里分享医疗健康领域个人数据的重要性以及获取个人数据的。

造就Talk第208位讲者 郑杰
-
树兰医疗总裁
-
OMAHA开放医疗与健康联盟发起人
大家好,我是郑杰,来自于杭州。我出生于一个医生世家,也在医院边上长大,但大学里我读的是计算机专业,毕业后我也没当医生。不过我很开心地发现,最近这些年我做的事情和医学发生了关联。
现在我正在运营一个全新的医疗集团,但是我的业余时间在做一个叫OMAHA(开放医疗与健康联盟)的联盟,今天我的分享和我做的事情有关联。我的演讲题目叫做:我的医疗数据,我做主 。
医患关系变化的背后是什么?

大家看到的这个logo是美国医学会的一个图章标志,中间它有一个蛇杖,是以前西方医学神的图腾 。我发现,很多的医疗机构和卫生主管机构也把蛇杖放在他们的logo里。
在一百多年前,我们没有这么多的高新科技,问诊都靠身体触摸。在那个年代,一个女性,除丈夫之外其他能触摸她的男性,就只有医生,所以医生的地位是非常神圣的。但到了这个时代,医患关系正在发生改变。

举个小例子。我的一位大学老师不幸患了癌症,他闭门不出三个月,读了所有这方面的资料、论文,然后到医院,指着一叠东西对医生说,大夫,你按照这个方法给我治吧,结果医生傻眼了。
这说明什么?说明这个时代的医患关系正在发生变化。
那变化的背后是什么?是数据。

以前看病是靠望闻问切,现在的医疗都依赖于数据,依赖给你量化以后采集的信息来做判断。那么这个数据会怎么样呢?
一家基因测序公司帮我做过全基因组测序。 那么这样的全基因数据有多大?有90GB。同时,我们医疗数据的量还在不断的扩大,在不远的将来,我们每一个人的医疗数据都会超过一个TB。
那问题又来了,我们有多少人手里有自己电子化的医疗健康数据呢?
如何拥有完整的医疗健康数据?
你的医疗健康数据在哪儿?
这是一个非常重要的问题。我们以前经常拿着病例本去医院,那时候,医生还会往你的病例本里贴化验单。但最近我发现,我以前的好几个病例本都丢了,我相信大家也有同样的经历。
另外一方面,我们每个人一生中都会在不同的医疗、体检机构去接受相应的服务,所以你的数据都分散在不同的机构里面,而且全世界现在都面临这个难题。

我们如何才能拥有一个完整的医疗健康数据?为什么完整性这么重要?
我再举个例子,我有个很好的朋友,他在做肺部检查时查出来有个阴影,怀疑是肿瘤,去医院做了很多次会诊,最终不放心还是开了一刀,但开胸后发现不是瘤,这一刀白挨了。
后来他才想起来,自己早年当兵时得过一次严重的肺炎,如果他的医疗记录里有过这个病例记录,也许他就不用挨这一刀了。
所以,这些看似和我们没有关系的医疗数据却和我们的生命息息相关。
那这里我分三个方面来谈谈医疗数据:数据开放、数据汇集和数据利用。
数据开放势不可挡
首先聊聊数据开放,目前我们拥有数据的医疗机构还没有完全打开,也不知道怎么打开,更不放心把数据给到患者。但同时,很多的企业和又很希望建立一个平台,把医疗数据收集起来。
我们可以参考下美国的实践。2010年,美国成立了一个名为马克基金会的第三方组织,这是由很多退休官员组成的一个非营利组织,主要目的是去讨论,如何让老百姓能够拥有完整的健康档案。他们经过反反复复的讨论,最终得出结论:要把数据直接给到患者。

于是,他们发起了这个名为 “blue button”(蓝扭)计划的行动,这个计划要求所有医疗机构、保险机构,在它的面向患者服务的网站上面,都要放一个蓝色按钮,可以让老百姓点击下载自己的医疗数据。
他们把这个行动推广到全美,这也启发了我们去做OMAHA 。

当下,也正在发生变化,深圳市在去年发布了卫生基本法,其中第一次把向患者公开病例写了进去,要求医疗机构在患者看完病之后的6小时内提供病例的查询、复印和复制服务。
复印大家都可以理解,但复制两个字却更加意义深刻,因为这要求医院能够电子化的数据复制给你。
现在,国内已经有一些医院可以给你一张数据光盘,以后有可能给你一个U盘 ,你可以把自己在这家医院的所有医疗数据带走。

这当然是一步一步来,可以先是一个PDF,再慢慢走向一个计算机可以直接读取的格式,这是我们的一个终极目标。也就是说,这个医院给了我一个电子化的U盘,里面的文档到了另外一个医院可以直接导入,这应该成为一个行业的共享规则。
很多医院担心把完整病例给了患者以后会惹上医疗官司,还有很多医院里的数据其实不完整,它羞于拿出来。但恰恰有些院长会说,这不是很好嘛,我和患者非常透明,他可以反向来监督我们,让我们医生更认真的去写病例。
这是真正以患者为中心的医院会有的考虑。我们很幸运地看到这样的医院越来越多了。
不同数据该怎么汇聚?
开放之后还有第二个问题,数据要怎么汇聚?
大家都知道,在医疗行业里,不同医院之间的一些指标的正常范围、专业术语都不一样,那这个数据拿出来之后,你能整合成一份吗?
有些企业正在想办法解决这个问题,比如苹果公司,苹果手机里有一个health的功能,他就希望变成你的健康数据的一个桥接器、汇总器。所有和苹果手机连接的APP和可穿戴设备,只要你将血压之类的体征数据储存进去,它就可以来帮你做数据的汇总。
但如果我今天从苹果手机换到Android手机怎么办?换到小米手机怎么办?换到锤子手机怎么办?
所以你会发现,健康数据的汇总是一个工业级的标准,我们在反复思考应该怎么做,要帮行业做哪些基础设施以解决基础性的难题。
这里很重要的一点就是文档格式和术语标准。

大家都知道AlphaGo,它之所以成为围棋高手,是由于学习了两千多万个棋谱,不管是版的棋谱还是国外版的,都可以作为一个文档被保存下来,而全世界共享的是同一套标准。
同样,我们的健康医疗的文档格式是什么,这是我们需要去考虑的。
其次就是术语标准。大家可能不知道,医疗界对一些术语的描述还是非常个性化。举个例子,有一些医院叫“盲肠炎”的部位其他医院叫“阑尾炎”,但讲的是一回事。
怎么样才能把这些不同的术语汇聚整合并进行统一?

所以我们搭建了一个协作运营的平台,让大家来共同维护一些词条,建立它们的关联关系。我们做的事,就是要给整个中文医学术语体系搭建一个行业基础设施,就像对于电商而言,要搭建基本物流设施一样。
完整的医疗数据有什么用?
假设有了数据汇总的分析设施,那么它能带来什么?
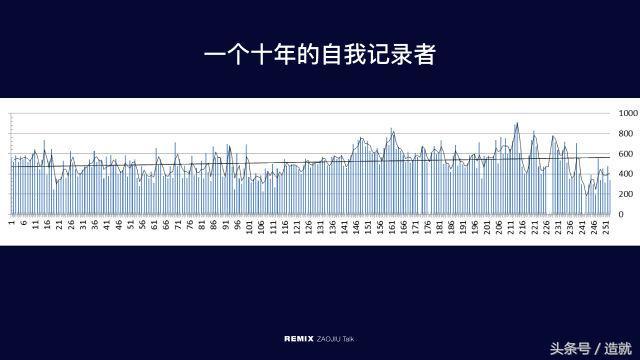
这里我举一个例子,这是我的一个好朋友,一个40多岁的理工男,他不幸得了严重的痛风,要经常检测自己的尿酸,他不间断给自己测了十年尿酸,还把这些数据填到excel表格里面去,还给它做了回归线分析。
他说要自己填写数据实在很麻烦,要是每次测的时候都有个软件能自动汇总就好了,同时这个软件还能提醒我到了什么时间点该做什么。
这就是很直接的一个例子,如何将他十年的数据自动汇总完整性 。由此可见,一旦你生病以后,真的就非常关注自己的数据了。

当我们有了完整的数据以后,我们还可以享受到个性化的治疗。我们都知道现在西药不是对每个人都有效,也许你对这个药有效,他对这个药无效,你应该吃三颗,他要吃五颗。
所以,医疗如今已进入到了一个长尾时代,不仅是个性化治疗,而且将会有越来越多的疑难杂症、罕见病,都在这个数据完整的时代被发现。
保障数据利用的安全
随着数据越来越多、越来越完整,我们还会碰到一个更直接的问题,就是如何保障隐私安全。事实上未来我们自己的健康数据的价值非常重大,也许很快会和你的保险来做对接。
我们每个老百姓既有权获得自己的数据,又要非常关注隐私问题。

世界上已经有很多国家对此制定了相应的法律,也在慢慢的完善。医疗机构如果随便把患者数据给到第三方,是有重大问题的。
如果把自己的完整电子病历给到第三方机构,他们也可以精确定位你的信息。甚至于,就连你的声音信息都很宝贵,如果你的声音信息被采集,你以后甚至都不知道给你打。
在这个时代,你必须重视数据隐私和数据安全。不单是我们整个健康医疗大数据的流动汇总,不单单是第三方机构,更是所有老百姓、机构都要去关注和重视,整个产业界要去推动,这是一个全行业的事情。
数据时代的赤脚医生

上世纪五六十年代的时候,有一个被联合国高度认可的赤脚医生模式。我的母亲就做过赤脚医生,当年在乡下,她和父老乡亲关系特别好。
那时候的医生,真的是基于患者的大数据,来给对方做诊断的。那时候也没有什么设备,就是在跟患者聊天、交流的过程中来了解对方。
在未来的数字医生时代,全新的赤脚医生将来到你家门口。他在知道你的完整数据之后,可以给你做出更精准的诊断。
我们要重视自己的数据,要更加主动的参与自己的健康保障,这个化医疗的时代就要来临。

所以我们说医改也好,医疗服务行业也好,最终的目标都是让每一个人能够做好自我管理。只有做好自我管理,这个国家的医疗总费用才是最低的。
而自我管理的背后就是了解你自己,你有你自己完整的数据,而且大家又在共享数据,才能去发现更美妙的事情。
我们一起努力吧,谢谢!